如何实现一个简单易用可扩展的导表工具
米娜桑, 我又回来更新了. 这次回归正业, 聊聊几个月前写的一个简单的游戏配置导表工具 konfi. 起因是 side project 里手写的配置越来越多了, 在配置变得混乱前, 想着还是尽早转移到 excel 管理为好. 于是咱需要一个 excel 的导表工具, 这通常也是游戏项目的基础设施之一.
为什么写了 konfi
本着找到能用的就绝不手写的原则, 一番检索后, 试了下被提到最多的 Luban. 毫无疑问, 这是一个强大且成熟的导表框架, 有着非常丰富的特性. 但我觉得它在易用性以及和我项目适配上并不太理想. 其配置语法在我看来也还是有点繁琐的. 并且导出的数据格式主要是基于 json, 然后可根据需要再转成其他语言的数据结构. 我个人认为用 json 去描述游戏配置信息并不够好, 比如 json 竟然不支持用整数做 key, 而用整数 id 做主键的配置表则非常普遍. 其实最理想还是直接把配置导出为所用编程语言的数据结构, 在保留信息的同时也方便读取. 另一方面, luban 对于我的项目而言实在有点过于庞大了, 有太多我几乎用不上的特性, 其源码都是我项目的好几倍了… 于是, 我又尝试了一些实现较简单的开源工具, 但大多又已年久失修. 最后想着这类工具反正是一劳永逸的, 需求也不会特别复杂, 不妨就自己实现一个算了.
konfi 的实现也参考了其他的导表工具的设计, 但总体原则是简单, 易用, 可扩展. 简单指核心实现不到千行, 只实现最常用的基础功能. 易用是希望无需额外配置, 直接建表即可运行导出, 配置语法简洁, 统一且符合直觉. 可扩展则是说可以方便地增加或修改导出流程和数据类型, 从而更好地适配项目. 接下来就简单聊聊如何使用以及如何扩展 konfi, 就当是 konfi 的使用文档了. 嘛, 话虽这么说, 其实也不算安利啦, 更多是分享一个思路, 毕竟 konfi 本身就是缺少测试的, 除非你觉得可以解决使用过程中出现的任何问题. 另外, 有些好用但我目前用不上的特性仍在斟酌中, 也暂时没有实现, 在后面会简单提一嘴.
如何使用 konfi
使用篇
有必要先说明一些基础设定. 一般比较常用的有三种配置表, 即枚举表, 数据表, 键值表. 枚举表用于配置项目中的枚举, 便于在整个项目中引用, 比如职业就可以是一个枚举类型, 有剑士, 小偷等职业. 有了枚举之后可以在项目或数据表中引用. 数据表通常包含了最主要的配置内容, 比如游戏中的角色, 物品信息等, 有非常多的属性数据, 角色此时也应当可以使用职业枚举来配置其职业属性. 键值表包含最简单的 key-value 结构, 用于简单的字典结构数据或杂项配置. 以上也可以看出枚举表应该比其他类型的表优先处理, 这样才能引用枚举表的数据.
在这个 repo 的 design 目录中有两个示例的 excel 表格, 演示了常用的一些配置方法. 枚举表因为需要优先导出故通常作为单独的 excel 文件. 为了导出 design 内的配置表, 可以直接运行 export_table.py 这个脚本, 配置将导出到 data 目录下.
运行环境 Python 3.11+, 依赖包括 openpyxl(excel 文件读取) 与 black(Python格式输出).
1 | from konfi import Exportor |
枚举表
先看 枚举.xlsx 文件内容.
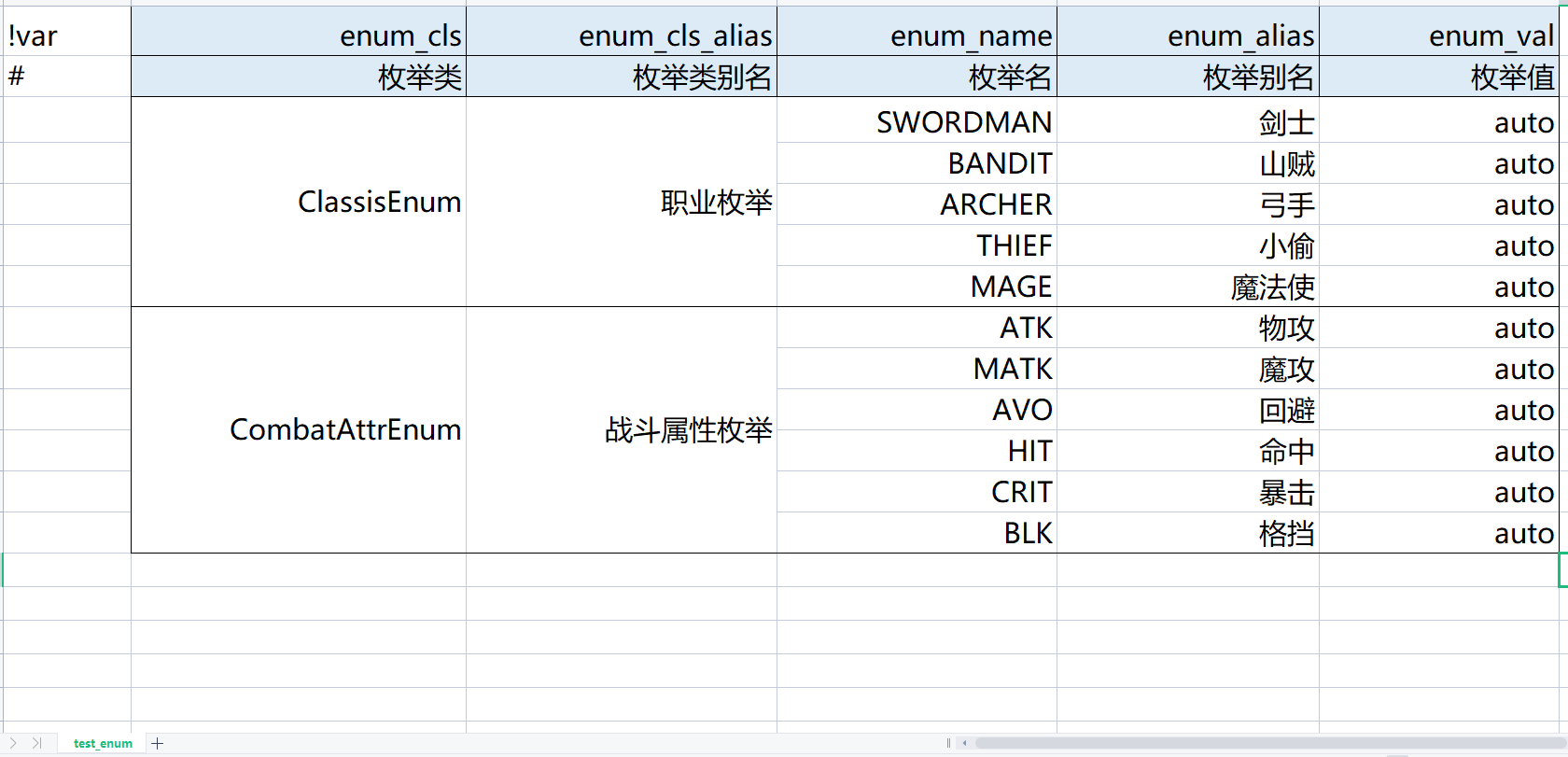
test_enum 这个 sheet 中配置了两个枚举类型, 导表过程会先读取一个目录内的所有 excel 文件, 然后逐文件, 逐 sheet 进行导表操作. 使用 _enum 作为后缀名的 sheet 会视为枚举表, 并用枚举表的导表规则进行导出.
konfi 要求表格内容划分为三个区域, 首先是保留的第一列, 主要用来对单行的内容做标记, 比如标记哪些行是配置行. 在上面的例子中, 使用 !var 标记了枚举表所需的一个配置行, 使用 # 标记了一个注释行. 然后是配置行, 配置行的每一列用于描述该列的数据是什么. 枚举表要求 !var 的配置行有 enum_cls, enum_cls_alias, enum_name, enum_alias, enum_val 这 5 列. 最后则是数据行, 即除第一列和配置行以外的右下区域.
以导出 python 数据结构为例, 这个枚举表导出的内容为1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24# 枚举.xlsx/test_enum
# export by konfi
from enum import Enum
class ClassisEnum(Enum):
""" 职业枚举
"""
SWORDMAN = 0 # 剑士
BANDIT = 1 # 山贼
ARCHER = 2 # 弓手
THIEF = 3 # 小偷
MAGE = 4 # 魔法使
class CombatAttrEnum(Enum):
""" 战斗属性枚举
"""
ATK = 0 # 物攻
MATK = 1 # 魔攻
AVO = 2 # 回避
HIT = 3 # 命中
CRIT = 4 # 暴击
BLK = 5 # 格挡
konfi 目前也支持导出 lua 与 json(通过修改 writer_ext 为 lua 或 json), 但我自己只使用 python, 故其他格式的导出支持可能没那么完善. 但理论上通过扩展, konfi 是可以导出任何格式的数据的.
关于枚举表的一些细节
- 枚举值一列需配置整数, 也可以和 python 枚举一样使用 auto 让 konfi 自行决定枚举值.
- 枚举类型在其他配置表中被引用时, 可以使用 枚举名 或 枚举别名 进行配置, 这一点后面我们会看到例子.
- 没错, 使用 # 进行注释也借鉴自 python. 在 konfi 中, 这是一个统一的注释语法, 使用 # 不仅可以注释行, 写在配置行的里也可以注释列, 甚至可以写在 excel 或 sheet 名字前进行注释. 被注释的内容会跳过导出处理.
数据表
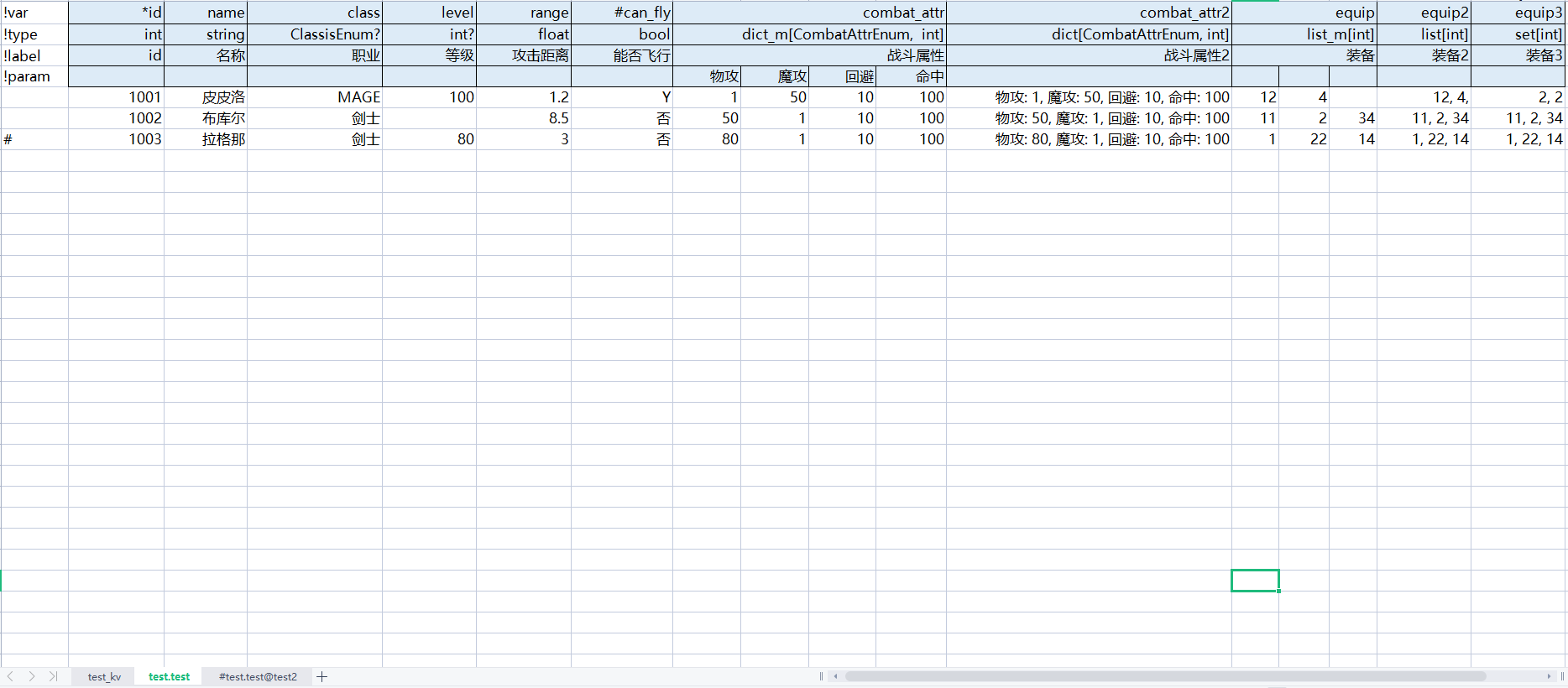
接着我们看内容最复杂的数据表, 测试.xlsx/test.test
上表导出的 python 数据结构为1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61# 测试.xlsx/test.test
# export by konfi
# id : int id
# name : string 名称
# class : ClassisEnum? 职业
# level : int? 等级
# range : float 攻击距离
# combat_attr : dict_m[CombatAttrEnum, int] 战斗属性
# combat_attr2: dict[CombatAttrEnum, int] 战斗属性2
# equip : list_m[int] 装备
# equip2 : list[int] 装备2
# equip3 : set[int] 装备3
from ...enum import ClassisEnum, CombatAttrEnum
test = {
1001: {
"id": 1001,
"name": "皮皮洛",
"class": ClassisEnum.MAGE,
"level": 100,
"range": 1.2,
"combat_attr": {
CombatAttrEnum.ATK: 1,
CombatAttrEnum.MATK: 50,
CombatAttrEnum.AVO: 10,
CombatAttrEnum.HIT: 100,
},
"combat_attr2": {
CombatAttrEnum.ATK: 1,
CombatAttrEnum.MATK: 50,
CombatAttrEnum.AVO: 10,
CombatAttrEnum.HIT: 100,
},
"equip": [12, 4, 0],
"equip2": [12, 4, 0],
"equip3": {2},
},
1002: {
"id": 1002,
"name": "布库尔",
"class": ClassisEnum.SWORDMAN,
"level": None,
"range": 8.5,
"combat_attr": {
CombatAttrEnum.ATK: 50,
CombatAttrEnum.MATK: 1,
CombatAttrEnum.AVO: 10,
CombatAttrEnum.HIT: 100,
},
"combat_attr2": {
CombatAttrEnum.ATK: 50,
CombatAttrEnum.MATK: 1,
CombatAttrEnum.AVO: 10,
CombatAttrEnum.HIT: 100,
},
"equip": [11, 2, 34],
"equip2": [11, 2, 34],
"equip3": {2, 11, 34},
},
}
注意到, 这里的 sheet 名是 test.test, 没有后缀说明是一个普通的数据表. 不过名字中使用了 . 作为分割, 点前面的部分作为这个表数据的模块名. 简单来说就是这个表导出的内容会放到 data/test 目录下. 如果没有模块名则会直接放到 data 目录下, 以便于数据管理. 通常同一个功能模块的配置表是单独的一个 excel 文件, 其中的 sheet 使用相同的模块名.
表的第一列出现了几个新的标记
- !var, 配置字段表示一列数据的变量名
- !type, 配置字段表示一列数据的类型名
- !lable, 配置字段表示一列数据的标签名, 用于增加额外说明
- !param, 用于解析列时提供一些额外的用户设定信息, 比如修改数据类型的解析方式. 后面会解释效果.
- 使用 # 进行了行注释, 可以看到第一行也用 # 注释了 can_fly 这一列.
另一个不同是, 数据表本质是一个字典结构, 所以会需要至少一个主键, 在 !var 配置行前加 * 表示主键, konfi 也支持多级主键.
类型系统
类型系统是导表工具要解决的核心问题之一, 一个完善的类型系统会使许多功能的实现成为可能, 比如将数据转成任意语言的原生数据类型, 支持扩展配置的数据类型, 以及进行数据字段的校验等等. konfi 也实现了一个非常简单的类型系统去支持上述这些特性.
类型支持
之所以需要类型, 是因为我们需要告诉游戏程序如何去理解这些配置数据, 比较常见的有整型, 字符串, 布尔类型等等基础类型. 还有一类被称作泛型类型, 或容器类型, 比如列表, 集合, 字典等. 目前 konfi 内置支持的类型有
| 类型 | 配置名 | 默认值 | 说明 |
|---|---|---|---|
| 整数 | int | 0 | |
| 浮点数 | float | 0.0 | |
| 布尔 | bool | False | 是/Y/1 为真, 否/N/0 为假 |
| 字符串 | string | “” | 不需要引号 |
| 列表(单格/多格) | list / list_m | [] | list[int], 默认使用 ‘,’ 分割项 |
| 集合(单格/多格) | set / set_m | set() | set[int], 默认使用 ‘,’ 分割项 |
| 字典(单格/多格) | dict / dict_m | {} | dict[int, int], 默认 ‘:’ 分割键值, ‘,’ 分割项 |
| 枚举 | 枚举类名 | 配置对应 枚举值 或 枚举别名 |
可以看到这些类型名也都取自 python, 泛型类型的配置方式也类型 python 的类型注释.
可空类型
如果一个指定类型的表格没有配置会发生什么? 例如上面例子中 布库尔的等级 这一数据格就是空的. konfi 也尝试引入了 可空类型(nullable) 这一概念, 用以避免 默认值 与 空值 带来的混乱. 通过在任意类型后加 ? 标记一个类型为可空类型. 可空类型在解析一个空格时会作为空值处理, 在 python 中就是 None. 否则会解析为类型的默认值. 所以上面布库尔的等级其实是导出的 None.
枚举类型
枚举类型是一个非常特别的类型, 因为其依赖枚举表导出的数据. 其使用的配置名即枚举表中的枚举类, 例如上面的 职业 这一列, 使用了枚举表中的 ClassisEnum. 而数据可以填 枚举值 或 枚举别名. 其他用法上与基础类型无异.
泛型类型
konfi 支持的每种泛型类型都有两种配置版本, 单格 与 多格, 可以参考 combat_attr, combat_attr2, equip, equip2 的配置方式. 前面提到 !param 这个标记, 对于单格泛型类型可以用这个标记的配置去修改默认的解析分隔符. 之所以有这个需求是因为如果容器里的类型配置格式比较复杂, 容器默认的分隔符可能被占用, 此时就需要换一个符号来分割. 而对于多格字典类型, 目前使用该标记可以指定配置的字典 key 值.
扩展类型
konfi 支持自定义类型的扩展, 可以自行决定如何解析配置的数据, 不过会需要一些 python 的编码.
分表
另外 konfi 也实现了一个简单的分表功能, 可以把一张大表拆成多个 sheet 进行配置, 在导出时合并为一个整体. 需要保证合并的表的配置行一致. 在例子中有 测试.xlsx/#test.test@test2 这张表, 因为使用了 # 对 test.test@test2 进行了注释, 所以没有导出. 去掉 # 将其导出时, @ 之前的部分表示这个子表在导出时应该合并到 test.test 这个表的数据中.
分表的功能在大型表拆分时会有用, 我暂时是用不到这个功能了, 所以缺少测试.
键值表
键值表是最简单的一种配置表, 通常只需要两列配置项 key 与 val, 例如 测试.xlsx/test_kv, 使用 _kv 后缀的即视为键值表.

导出的 python 数据为1
2
3
4
5
6
7# 测试.xlsx/test_kv
# export by konfi
# key: string 键
# val: int 值
test_kv = {
"移动距离": 5,
}
关于键值表其他就没什么可说的了, 我个人是感觉这个键值表功能上还是有点简单了, val 这一列只能是一种类型, 这在作为杂项表时不太便利. 我在考虑是否应该支持更动态的类型, 比如直接支持配置 python 数据或 json 数据, 这在某些时候还是挺方便的.
其他
以上就是 konfi 主要功能的使用方式了, 这里再补充一些细节和将来可能会考虑实现的特性(请不用抱任何期待)
增量导出
这个还是挺有用的, 特别是配置表比较多, 而改动比较少的时候. 姑且实现了一个简单的, 创建 Exportor 时传入 is_inc = True 即可开启增量导表. 开启后导表会在 data 目录生成一个记录每个 sheet 数据 md5 的 json 文件, 如果没有变化则会跳过导出.
表格依赖
在有些情况下需要规定数据表的导出数据的顺序, 比如进行一些导出后校验等等, 也即此时表格之间是存在依赖关系的, 当前在 konfi 中并没有处理. 仅有的顺序也只是保证 枚举表 的优先导出.
导表效率
选择 python 实现在一定程度上就是用编码效率换运行效率, 尽管如此, 其实也是可以加入多进程导表, 优化导出流程等加速的方案, 但是目前看不到实现计划, 反……反正又不是不能用!
通过配置生成类型
我觉得这算一个比较进阶的功能了(luban 已有实现), 增强了配置表的功能, 也降低了扩展自定义类型的难度. 实现设计上需要非常小心, 感觉弄不好就非常鸡肋. 不过我暂时也用不上就是了.
扩展篇
简单说下 konfi 实现和扩展的思路. 大体思路其实就是先把 sheet 转换为 python 特定的中间数据结构, 然后再把这个数据结构按导出语言进行重构, 写入到配置文件脚本.
konfi 的设计中划分了一些概念, 比如
- 导出器(Exportor), 用于控制整个导表流程
- 解析器(Parser), 用于把一个 sheet 解析为 python 中间类型数据. 每个解析器可以自行决定如何匹配及处理 sheet.
- 类型(EType), 即中间类型, 用于描述 sheet 配置数据.
- 写入器(Writer), 用于把中间数据按特定语言写入到文件导出.
其中的每个部分理论上都可进行扩展. 比如对于解析器, 首先需要继承 Parser 类, 然后有两种方式筛选该 Parser 期望处理的 sheet.
- 类变量 match 可以直接列出匹配解析 sheet 的名字
- 实现 filter 函数, 参数为 openpyxl 的 Worksheet
接着需要实现 parse 方法, 确定 sheet 的导出规则. 可以参考已有的数据表解析器(CommonParser).
类型扩展是更常用的, 比如下面这个用 python tuple 构造的位置类型.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22class EPos(EType):
""" 位置坐标
(x, y)
"""
etype_tag = "pos"
default = (0, 0)
def __init__(self, val: Any, nullable: bool = False):
super().__init__(val, nullable)
self._convert()
def _convert(self):
if self.val is None:
if self.nullable:
self.py_val = None
else:
self.py_val = self.__class__.default
return
try:
self.py_val = literal_eval(self.val)
except ValueError:
raise ValueError(f"无法将值 {self.val} 转换为 {type(self).__name__}") from None
扩展类型需要继承自 EType, 确定类型名, 默认值, 以及是否支持多格. 然后实现类型的转换方法 _convert. 目前的这些类型实现得都还是比较简单的, 暂时也没有做校验什么的.
Enjoy.
.
.
.
.
.
.
.
.
終わり